Overview
Since the dawn of time, only a few limited hand gestures have ever been available to the HoloLens developer, primarily the Air Tap. The “Air Tap” is given to the developer by a high level API, and is parallel to a click on a PC or a touch on mobile. These interactive limitations have led to many different contextual interfaces that pop up during the HoloLens experience, sometimes moving to stay in the user’s field of view. These interfaces can cause visibility issues, be subject to visibility issues of their own and typically house a limited number of options.
Last week at a hackathon I escaped this interactive limitation by building a gesture interaction system for the HoloLens using Microsoft’s Custom Vision Cognitive Service Machine Learning framework. Once you begin an Air Tap, the gesture system begins coloring in pixels around a position on the image corresponding to your hand position. When you lift your finger and conclude the Air Tap the generated image is then sent to the Custom Vision endpoint, which classifies the image as one of five gestures and returns that information as a JSON (JavaScript Object Notation) response.
This new gesture system uses Custom Vision to run the image on Azure through a custom Convolutional Neural Network (CNN) that I trained by sending images from my application along with their correctly identified gestures. To make this easier, I built a simple user interface that allows the user to select which gesture they were going to perform and then perform the selected gesture to train the system. On the Custom Vision Cognitive Service portal I then cleaned up the data, trained a new iteration of the CNN, and then set that new model as the default for the Azure endpoint.
Development Process
When we first came up with this concept we had a few concerns.
 Our first concern was that the Azure Custom Vision wouldn’t be able to reliably classify the gestures. To test this I created a fake data set of gesture images like the one shown in the image above using Microsoft Paint. I drew twelve pictures of circles, triangles and squares, then uploaded them to an Azure Computer Vision model for testing. After training the model on those thirty-six images, it was able to classify new images correctly over 95% of the time, proving Azure's capability to accurately classify basic line shape recognition on very low-resolution images. This result also alleviated our second concern that the image we would need to upload would have to be too large and cause too much input lag with the network delay.
Our first concern was that the Azure Custom Vision wouldn’t be able to reliably classify the gestures. To test this I created a fake data set of gesture images like the one shown in the image above using Microsoft Paint. I drew twelve pictures of circles, triangles and squares, then uploaded them to an Azure Computer Vision model for testing. After training the model on those thirty-six images, it was able to classify new images correctly over 95% of the time, proving Azure's capability to accurately classify basic line shape recognition on very low-resolution images. This result also alleviated our second concern that the image we would need to upload would have to be too large and cause too much input lag with the network delay.The next challenges was getting the generated image gestures to upload with appropriately formatted meta-data. I found it difficult to find basic examples of uploading an image file to the endpoint with Unity’s networking libraries and in the end had to encode the texture to a PNG, save that PNG to disk, load it back into a byte array and then convert that into a string that I could place into the JSON string I was sending.

By the end of the day I was able to populate my training set with generated images that looked like the image above. Notice how the question marks are greener on the bottom while the Z gestures tend to be more red and yellow. This is because the question marks begin at the bottom and go up, while the Z gestures start at the top and go down. This effect helps differentiate the generated images of a user’s gestures by encoding the direction and velocity of the gesture into the color and spacing of the pixels on the image. If I were to use an LSTM (Long Short Term Memory) model then I could encode things like direction, velocity and timing explicitly, and could likely improve prediction reliability while reducing the size of my JSON data payload, at the cost of increased setup time.
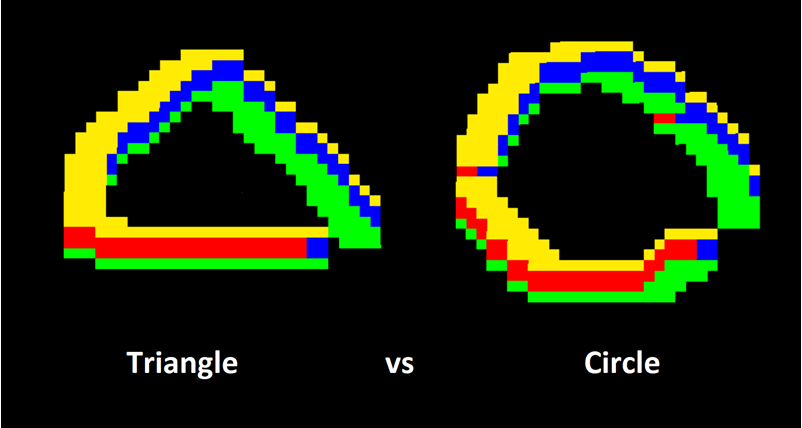 Switching to an LSTM might be necessary to support the gestures we want. I had originally started out with a different collection of gestures, like an X shape gesture and a triangle, but as the above image shows, those images were easily confused with the other gestures. So I tried new gestures until I found five with little to no overlap that worked with my simpler Custom Vision approach.
Switching to an LSTM might be necessary to support the gestures we want. I had originally started out with a different collection of gestures, like an X shape gesture and a triangle, but as the above image shows, those images were easily confused with the other gestures. So I tried new gestures until I found five with little to no overlap that worked with my simpler Custom Vision approach.The User Experience
I made a point to conduct several users tests as soon as I had the system running on the HoloLens. The first thing I realized during those user tests was that I needed a clear way to teach people how to do the gestures. In the video below, you can see an image of a circle that pops up when I tap the button like the picture below. The system has an image like this for each of the gestures, with a dot for the start point and an arrow showing direction. Future iterations and releases of the system will leverage custom animations for clearer demonstration of directionality.
During users testing, I also quickly noticed that one of the most common problems users were running into when trying to make the gestures is that their hands were going outside the hand tracking parameters/boundaries. Because of the delay between making a gesture and receiving a prediction for that gesture from Azure, users had a hard time knowing when or how they had made a mistake. To make this clearer I added an audible popping noise and made the gesture visual instantly disappear as soon as the user lifts their finger. This lets them know when the gesture is complete even before it’s classification is returned from the Azure Deep Learning service, making the experience vastly more tactile and usable.
If the gesture response comes back successfully a slightly deeper popping sound is played and a picture of the gesture type is shown in the bottom left corner. While the system doesn’t always predict the user’s intended gesture correctly, performing the gesture in a certain way can greatly improve the chance of recognition. By adding the noises and quickly removing in-view gesture tracking and predicted gesture classifications, the user receives clear, instant feedback when the gesture recognition fails and can adjust their technique accordingly.
There is one factor in using this style of gesture recognition that should be addressed when using it within an Extended Reality (XR) application. The system must be able to detect when the user is trying to use a hand navigation / tap+hold for something other than a gesture and know not to initiate a gesture action. In the demo video above you can see when control is enabled on the sphere, the user cannot perform a gesture while looking at the sphere. This must be accounted for in any system living alongside the gestures.
An important part of the experience of this new gesture system is being able to visualize the gesture as you’re making it. For times sake I did this with a single trail renderer attached to the user’s hand position. The constrained field of view / holographic frame of the HoloLens display made this challenging. Even though hand position is tracked well beyond the holographic frame, the user would not be able to see that indicated on screen. To remedy this, I moved the gesture visual a meter out and centered it on the user’s gaze so it would always be entirely visible.
While there is still plenty of room for improvement, the resulting ability to increase gesture options speaks loudly to us 3D developers who have grown accustomed to limitations. I’m excited to continue growing the system's functionality and add this interactive style to Valorem's toolbox and tech stack. As its capabilities grow, we will explore new ways to leverage the interactive gesture system within client applications to improve both customer and end user experience.
Another exciting path we want to explore with this Custom Vision model is using an ONNX export of it in conjunction with the WinML on-device inference that was introduced with the Windows’ RS4 update. My colleague René Schulte has already succeeded in running custom ONNX models on the HoloLens leveraging Windows Machine Learning for Deep Learning inference, without the need for backend calls. This will help to improve latency and also help to overcome potential issues with backend connectivity and network limitations.
If you are interested in learning more about this gestures system or Valorem's other Mixed Reality projects and solutions, email marketing@valorem.com or visit valorem.com to connect with our Immersive Experiences team.