

2025 Microsoft Inclusion Changemaker Partner of the Year
Valorem Reply is proud to announce that we have been recognized as winner of 2025 Microsoft Inclusion Changemaker Partner of the Year Award
Read More
In this article, we highlight the ongoing discussion between open-source and closed-source LLMs while showcasing the usefulness of Llama-2 and GPT-4.
Large language models (LLMs) are quickly becoming one of the most important tools organizations are seeking to leverage with their data teams. The dichotomy in the LLM space between open-source and closed-source has never been more pronounced as it is right now. The family of LLMs, Meta’s Llama 2 (open-source) and OpenAI’s family of LLMs GPT-4 (closed-source), are both brilliant choices in their own way. In this article we highlight the ongoing discussion between open-source and closed-source LLMs while showcasing the usefulness of Llama 2 and GPT-4.
Open-source versus closed-source
When organizations look to implement new technologies, they are often met with a singular question: Do we go open-source or closed-source. This has become even more critical as companies are rushing to implement the next wave of chatbots and AI services in the form of text or images. First, teams should be made aware of the arguments surrounding open-source and closed-source LLMs.
Open-source LLMs: Free but not always viable
Open-source models are by their very nature transparent, free, and provide a level of security that closed-source models do not. For example, Apple, Goldman Sachs, and Samsung have all banned or restricted of using ChatGPT for employees while at work due to risks of data leaks, cybersecurity risks, and fears over future regulatory compliance challenges. In contrast, open-source code is constantly reviewed and evaluated by the community, fostering well-documented security patches as well as details on how the base model was trained. However, many open-source models are not viable for commercial use. Llama 2 plans to fill this void, as it is free for commercial use and has performance that rivals GPT-3.5 on many standard benchmarks used in research and development of LLMs.
Closed-source LLMs: Premium LLM services without transparency
Closed-source models are models where certain information is withheld like training information and source code, which can inhibit developer creativity and reduces overall transparency on how a model’s output is determined. For example, tailoring your model to a specific dataset is a must-have for any company. AI tools like Dante can be used to train a GPT-4 into a personalized chatbot, but this comes at a cost. Regardless of which tool you use to achieve this level of customization, it is likely that you will be obligated to pay a subscription fee of some sort, not to mention the fee associated with GPT-4’s API calls. As for technical aspects, most closed-source models keep much of the training details secret like computing power required and hyperparameter values – information that might be useful for developers looking to build their own in-house model.
Llama 2 or GPT-4
Now that Llama 2 has been released, we have compiled a brief list of pros for each model, so you can make an informed decision on which one is more appropriate for your team if you are considering using either. For more information than what is covered in this blog’s overview, refer to the Llama 2 paper.
Llama 2
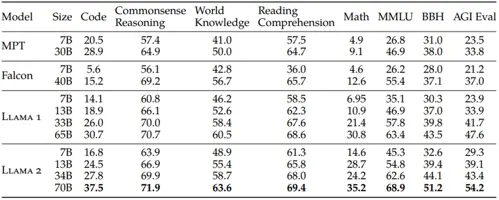
- Outperforms other LLMs like MosaicML and Falcon on chosen benchmark tests (see below).
- Novel improvement on safety and helpfulness on Llama 2-Chat models (which is Llama 2 but fine-tuned for dialogue). In fact, Meta claims this new family of models can potentially replace closed-source models in this regard. This makes the model a compelling argument for industry adoption.
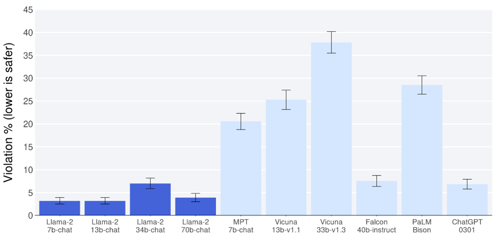
- Increased inference scalability in the larger models by using grouped-query attention (a relatively newer method of handling autoregressive decoder inference bottlenecks). That is, the model can handle large amounts of data quickly and efficiently.
- High performance and smaller model than GPT-4 that can be ran locally – ideal for scenarios where data security is a top priority, but you still want the GPT-like performance.
- During training, a mix of publicly available sources were used, and Meta took particular care not to use data from their products or services as well as removed data from cites known to have a high volume of personal information.
GPT4
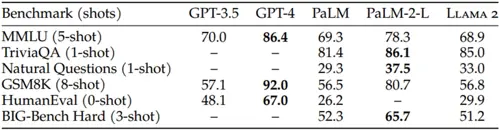
- Outperforms Llama 2 and Palm models on academic benchmarks. It is considered to be the gold standard for commercial-ready LLMs at the moment.
- GPT-4 is multimodal model, so it has use cases using text as input as well as images.
- Creativity and coherence - using GPT-4 as a base model, the user can generate images and poems with human-like results.
- Coding capability - Llama 2 falls below even GPT-3 with respect to usefulness in coding. GPT-4's benchmark evaluation registered at 67.0 while Llama 2 scored at 29.9 (see other evaluations below).
- Many companies have adapted their products to rely heavily on GPT-4 such as Duolingo and Khan Academy. This is a testament to the reliability GPT-4 in real-world applications.
If you would like to learn more about how you can utilize either Llama 2 or GPT-4 to meet your business needs, please reach out to us. Our AI experts are ready with solutions to your problems, whether they are simple or complex.
